Can ChatGPT replace our Research Assistants?
I’m not much of a science fiction reader, but a story that I read in middle school has always stuck with me. A. E. van Vogt’s 1944 short story “Far Centaurus” tells the story of a group of interstellar travellers on a generation ship who arrive at a far distant planet after centuries in space only to find that technological improvements on Earth in the interim mean that their destination has already been long since colonized by others who passed them along the way. When I read about alleged improvement in LLM technologies like ChatGPT I sometimes wonder about the work we’ve done so far on this project. Having worked on this project for a decade, is it possible that new technologies will simply be able to do what we have done in a fraction of the time?

van Vogt’s story was cribbed in Weird Fantasy #15 as a light-hearted three-pager with art by Al Williamson
Back in 2020, we hired thirty-three different Research Assistants to perform the highly unglamorous work of counting all of the panels on all of the pages of our scanned corpus - about 100,000 pages in total. Subsequently, a smaller number of those same RAs were employed to hand count all of the words in every word balloon, thought balloon and caption on all of those pages. This was a ludicrously time consuming task. When people ask “why isn’t this project finished yet?”, well, you hand count millions of words in thousands of comic books and get back to us.
With all of the hype around LLMs (erroneously referred to as AI) I have tended to wonder recently: has it caught up to the point where we could have automated that work? Has the faster than light spaceship just flown past us?
I have been skeptical because if I do query ChatGPT or other LLMs about our research questions its answers are always hilariously, wildly off-base. Its answers are so outside the scope of reality that I have no idea what people who “talk” to ChatGPT even think they’re doing. I read blogs by professors who claim to have important discussions with these tools and strain my eyes from rolling them so hard.
But, I thought, despite all that, surely the machine can count. Right?
Well, I ran a test a while back on ChatGPT 4.0 and found that the answer was no. No, it could not accurately count the panels on comic book pages that I uploaded to it. Of five sampled pages, three were incorrect. That was as far as I got. I walked away confident that we had done the right thing by relying on human RAs.
This week, however, a colleague forwarded me a piece about ChatGPT and CBR/CBZ files and it landed in my inbox around the same time as an email encouraging me to try ChatGPT 5.0. So I ran my van Vogt test again on two pages.
I have been working all summer and into the fall on coding page layouts on our 100,000 pages, which has given me a pretty good sense of how pages have changed over time. What I wanted to see was if ChatGPT 5.0 could accurately count relatively simple page layouts from the 1950s (which I guessed it would be able to) and more complicated layouts from the 1990s (which I doubted).
This is, to be blunt, the most basic task we have on the entire project. Given that ChatGPT 5.0 is marketed as “having a team of PhD level experts in your pocket” it should, we figured, be able to count to seven.
And the good news? It can count to seven.
This is the first page that I gave it: the second story page from Coo Coo Comics #53 (Standard Comics, 1953):

ChatGPT correctly identified this page as having seven panels, and was not thrown by the borderless third panel. Great job!
But then I asked it to the next task that we had our RAs do: Tabulate the number of words on the page.
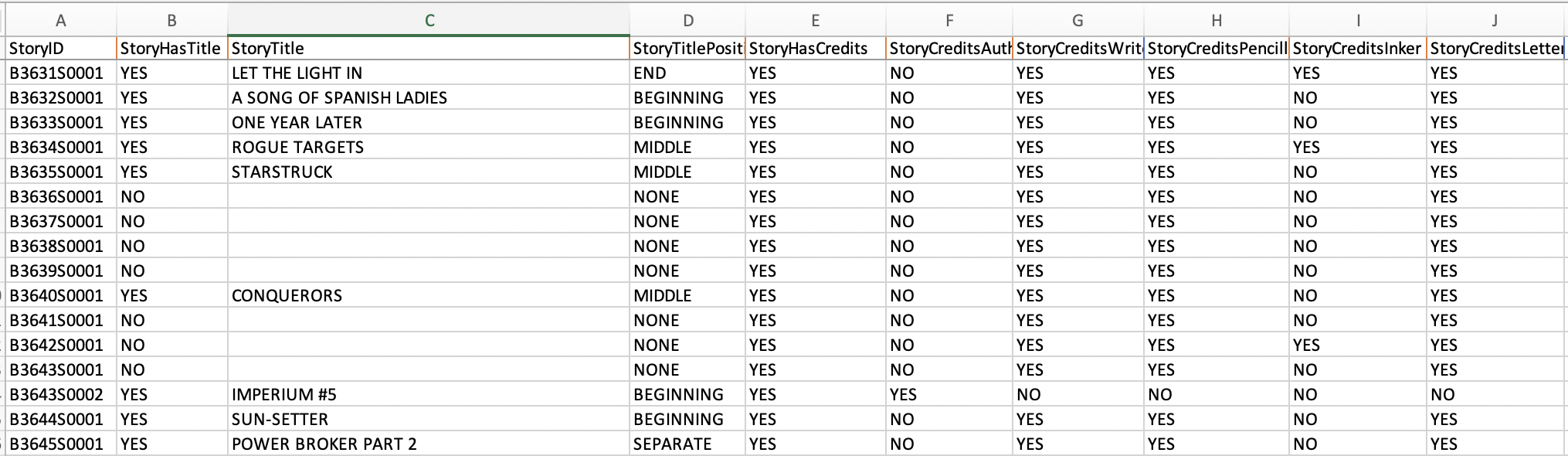
This was a problem, because as, you can see below, our RA recorded that there are 161 words on the page. A pretty substantial difference of opinion on a factual question.
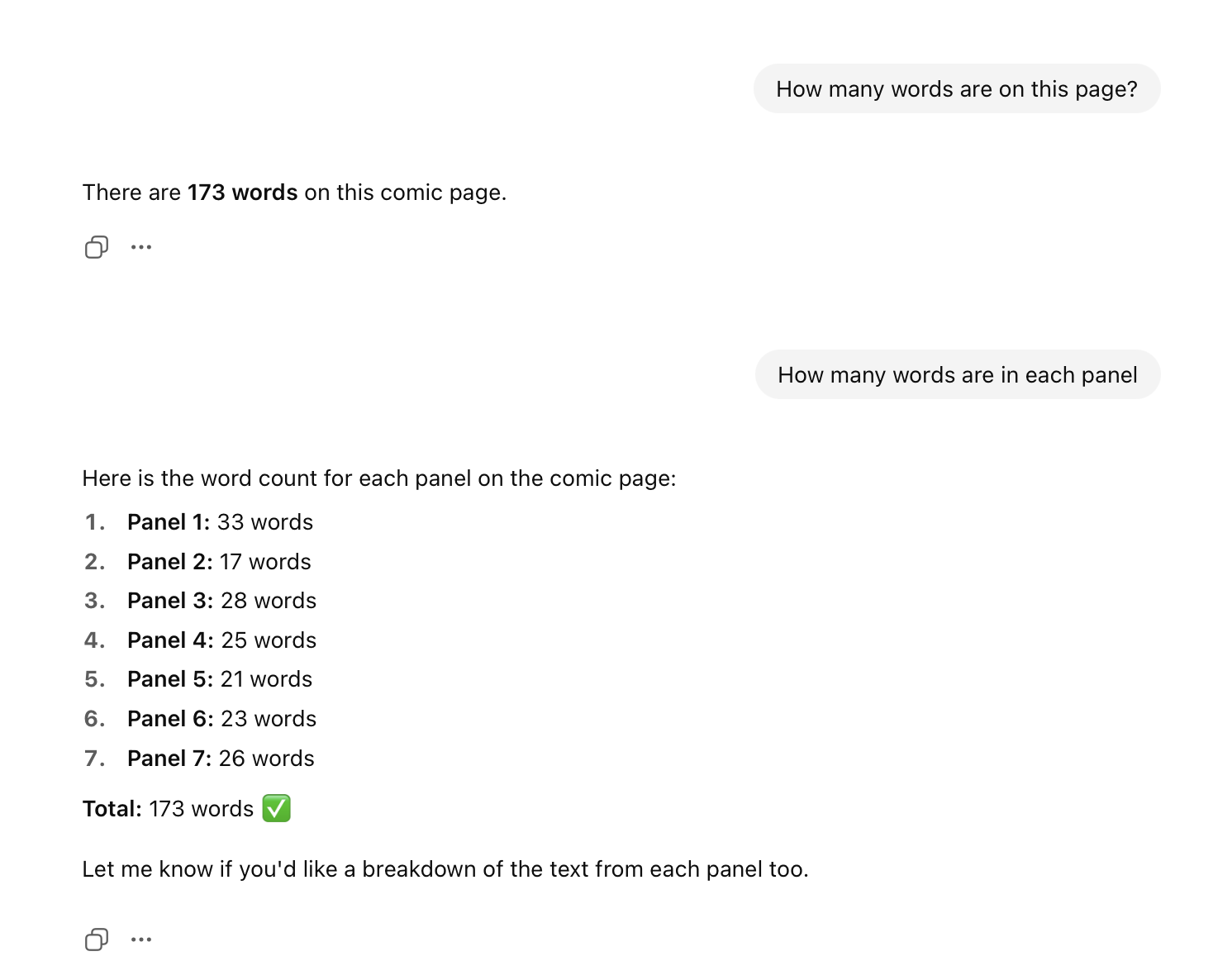
So I prompted it again, asking it to give me a breakdown by panel and it did so, telling me that Panel 1 contains 33 words. Take a look for yourself:

Our RA counted those two balloons and came up with 22 and 3 words, for a total of 25. ChatGPT miscounted by eight words. I could not, for the life of me, fathom how it could have gotten that very basic fact incorrect. So I prompted it again, asking for a transcription of the text.
This is what it gave me:

First, ChatGPT misattributes the dialogue to the characters (Roscoe is in green and yellow, Ichabod is the one with no clothes….) but, more importantly for our purposes, ChatGPT provides a transcript that is - and you can count the words for yourself - 25 words long, and then confidently labels it 33, doubling down on its initial error. This is not PhD level work.
(Also, and this might be picking nits, but changing “thwilling” to “thrilling” in the transcript is alarming if we wanted to do lexical analysis)
What was worse, however, is that ChatGPT continued to make ever more mistakes. You’ll notice that the second panel on the page is wordier than the first (containing 36 words) but ChatGPT reported it as half as wordy, with only 17 words. How could this be? This is its transcript:

Here ChatGPT transcribed (accurately, to be fair) only the first word balloon. It then miscounted the words (there are 20, not 17 as it repeatedly states). But it only did half the job.
Worse, ChatGPT did notice that word balloon but it ASSIGNED IT TO THE NEXT PANEL:

First: Big miss on the word count as 16 words are reported as 28. Second: It added a hyphen to “make believe”, changing the number of words, and actually making it even less accurate. Third: Soupie (as in Supermouse, the lead character in this series) is now Sopie for some reason. Fourth: THIS ISN’T THE THIRD PANEL
I’ll stop, but trust me when I say that the errors only compound from here. Having gotten the order of the panels wrong, ChatGPT clings to the error and ultimately just stops counting the text entirely at the bottom of the page. PhD level expert? I know eight year olds that could do this job more accurately. Moreover, I don’t think ChatGPT could actually label the scans that we have, which is necessary for all the further work that we do. We need accurately annotated pages to even begin doing our work.

An actual PhD student counted this
So, I should have just let it go at that point but I was curious as to what it would do with a less traditionally laid out page. One of the significant shifts in the page design of American comic books is the shift, particularly pronounced in the 1990s, towards pages that eschew the traditional gutter for a single line, and also for panels that are either fully inset within other panels, or intrude into their space.
The page I gave it was from Dollman #2 (Eternity Comics, 1991), with art credited to Marcelo Campos. This is a much busier page than the Supermouse page, with two tiers and four inset panels, three of which overlap each other). To its credit, ChatGPT nailed this as six panels.

And then everything went to hell.
First, it counted 193 words on the page rather than the 143 that are actually there. But that massive error was the least of our problems. When I asked it for a transcript, well, frankly, it went insane.
Take a close look at the third panel:

And now read the text as ChatGPT reads it:

With all of the reports of the hallucinatory nature of ChatGPT this shouldn’t have suprised me in the least, but, well, I was surprised. ChatGPT presumably picked up on the “Dollman Finds Elvis” text and then just started adding its own Weekly World News style headlines.
But it wasn't done.

I guess that ChatGPT sees the words “Los Angeles” and immediately jumps to gang violence, because this is how it transcribes this panel’s text:

Having started down this path, ChatGPT simply continues to dig. This is the reality of panel five:

And this is what ChatGPT decides it should be:

Having introduced the gang theme, it simply sticks with it. Not sure where the “woman he loved” comes from.
There’s more, but why bother? ChatGPT is off in its own little world, far removed from the work we’re doing.
We have been working on this project for more than a decade now. It has been a long, slow process that is starting to feel like a generational journey. But it is absolutely safe to say that, despite all their hype, the faster than light ships meant to replace us are exploding on their launchpads like so much SpaceX debris.
To answer the question posed in the title: Hell no. Not even close.
We hired three new RAs today.